Abstract
We introduce a probabilistic splat-based radiance field framework that retains the fast rasterization and test-time efficiency of 3D Gaussian Splatting (3DGS) while replacing heuristic primitive manipulation with gradient-based optimization of a volumetric probability density. Rather than relocating, splitting, or culling Gaussians via hand-tuned densification (e.g., ADC), we treat primitive locations as samples drawn from a persistent, learnable density. We instantiate this density using a novel, memory-efficient multi-scale hierarchical grid that enables end-to-end gradient-based optimization. To stabilize the optimization, we derive an unbiased gradient estimator with control variates that markedly reduces variance. By allowing probability mass to flow to where the loss demands, our framework eliminates brittle priors and naturally explores the volume, achieving state-of-the-art reconstruction quality on mip-NeRF 360 while preserving 3DGS-level rendering speed.
Video
Methodology

We represent the scene as a hierarchical probability density function \(p_\theta(\mu)\), along with hash grids \(\phi\) that store Gaussian attributes (color, opacity, scale, rotation) at each position. At each training iteration, we sample Gaussian centers \(\mu_i\sim p_\theta(\mu)\), look up their attributes \(\phi(\mu_i)\), and render the resulting Gaussians with a training camera \(\pi_k\). The expected rendered image is given by \[ I_k = \mathbb{E}_{\mu_0,\ldots,\mu_{M-1}\sim p_\theta(\mu)}\left[\mathrm{Render}\!\left(\pi_k,\{(\mu_i,\phi(\mu_i))\}_{i=0}^{M-1}\right)\right]. \] and we update \(\theta\) and \(\phi\) so that the expected rendered image matches the corresponding training image. The gray arrows indicate the resulting gradient flow.
Hashed Probability Pyramid
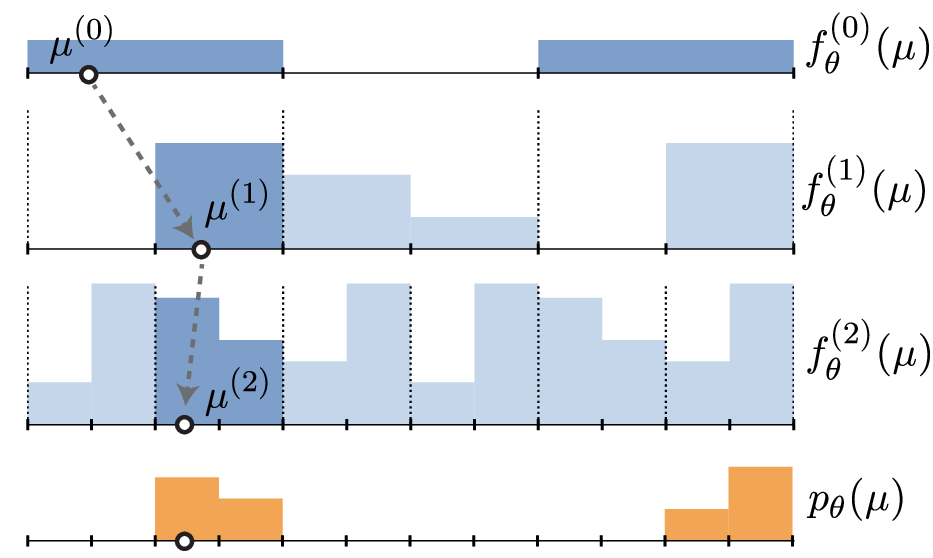
We create a volumetric piecewise-constant PDF without cubic growth in parameters by defining a hashed pyramid. Each level is a piecewise-constant function over the volume, and the full distribution is given by \[ p_\theta(\mu) = \frac{1}{Z} \prod_{\ell=0}^{L-1} f^{(\ell)}_\theta(\mu). \] Each bin at level \(\ell\) is subdivided into a normalized \(2 \times 2 \times 2\) PDF at level \(\ell+1\). Sampling is done hierarchically: we first choose a coarse bin, then recursively sample finer distributions that localize the point within progressively smaller regions of the volume. At deeper levels, parameters are shared between subdivisions. In the one-dimensional example above, blocks 1-3 and blocks 4-6 at level \(\ell=2\) are identical, so the pyramid represents a sparse 12-bin piecewise-constant PDF using only 8 instead of the usual 11 parameters. In three dimensions, we represent a 40963 grid with 86 million parameters, reducing memory by 800x compared to storing a dense grid.
Optimization
We stabilize training by designing a low-variance unbiased estimator for the gradient with respect to pyramid parameters \(\theta\): \[ \nabla_\theta \, \mathbb{E}_{\mu\sim p_\theta(\mu)}[I] = \mathbb{E}_{\mu\sim p_\theta(\mu)}\left[\sum_{i=0}^{M-1}(I-I_{-i})\cdot\nabla_\theta\log p_\theta(\mu_i)\right], \] This control variate estimator isolates the contribution of each Gaussian splat \(i\) based on the difference \((I-I_{-i})\) between the image rendered with all Gaussians and the image rendered with all but the \(i\)-th one. Surprisingly, these differences arise within the autodiff of attribute parameters \(\phi\), so they are computed without additional rendering passes.
Results
Comparisons

Videos
Garden
Playroom
Counter
BibTeX
@inproceedings{polansky2026eulerian,
title={Eulerian Splatting using Hashed Probability Pyramids},
author={Polansky, Mia Gaia and Kopanas, George and Garbin, Stephan and Zickler, Todd and Verbin, Dor},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}}
Contact
For questions or collaborations, please reach out:
Email: miapolansky@gmail.com